


This article has not been completed yet. However, it may already contain helpful Information and therefore it has been published at this stage.
Setting up the environment:
Return to the Dataexplorer and the Cluster, you created in the onboarding challange:
https://dataexplorer.azure.com/home
Script to be executed:
.execute database script <|
// Create table for the books
.create-merge table Books(rf_id:string, book_title:string, publish_date:long, author:string, language:string, number_of_pages:long, weight_gram:long)
// Import data for books
// (Used data is utilzing catalogue from https://github.com/internetarchive/openlibrary )
.ingest into table Books ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/books.csv.gz') with (ignoreFirstRecord=true)
// Create table for the shelves
.create-merge table Shelves (shelf:long, rf_ids:dynamic, total_weight:long)
// Import data for shelves
.ingest into table Shelves ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/shelves.csv.gz') with (ignoreFirstRecord=true)

The Challenge:
This was supposed to be a great day for Digitown’s National Library Museum and all of Digitown.
The museum has just finished scanning more than 325,000 rare books, so that history lovers around the world can experience the ancient culture and knowledge of the Digitown Explorers.
The great book exhibition was about to reopen, when the museum director noticed that he can’t locate the rarest book in the world:
"De Revolutionibus Magnis Data", published 1613, by Gustav Kustov.
The mayor of the Digitown herself, Mrs. Gaia Budskott – has called on our agency to help find the missing artifact.
Luckily, everything is digital in the Digitown library:
– Each book has its parameters recorded:
number of pages, weight.
– Each book has RFID sticker attached
(RFID: radio-transmitter with ID).
– Each shelve in the Museum sends data:
what RFIDs appear on the shelve and also measures actual total weight of
books on the shelve.
Unfortunately, the RFID of the "De Revolutionibus Magnis Data" was found on the museum floor – detached and lonely.
Perhaps, you will be able to locate the book on one of the museum shelves and save the day?Table Analysis:
Tables to be used for this task:
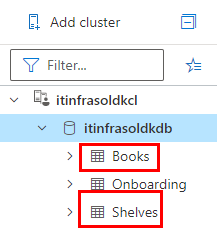
# Show 10 books
Books | take 10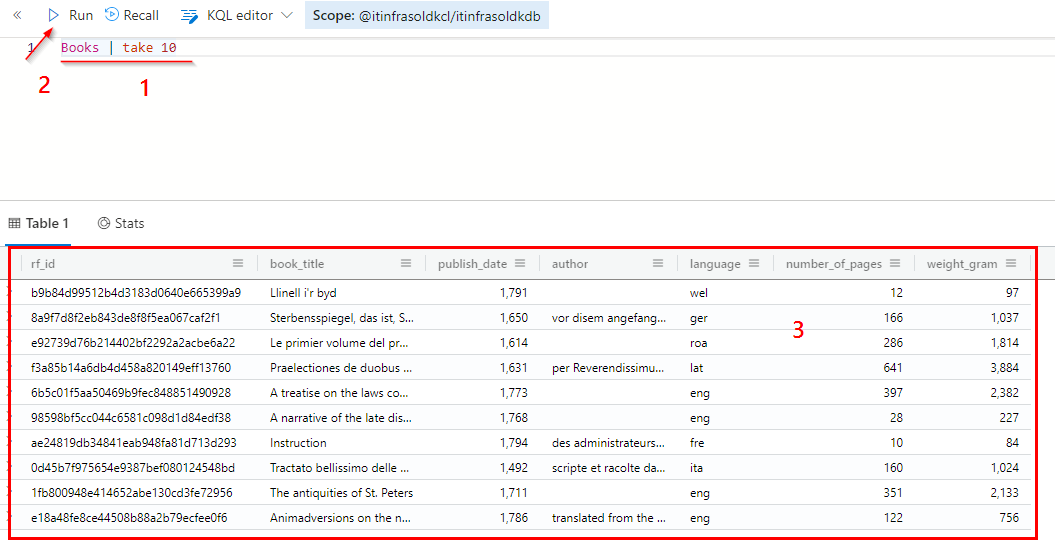
# Show 10 Shelves
Shelves | take 10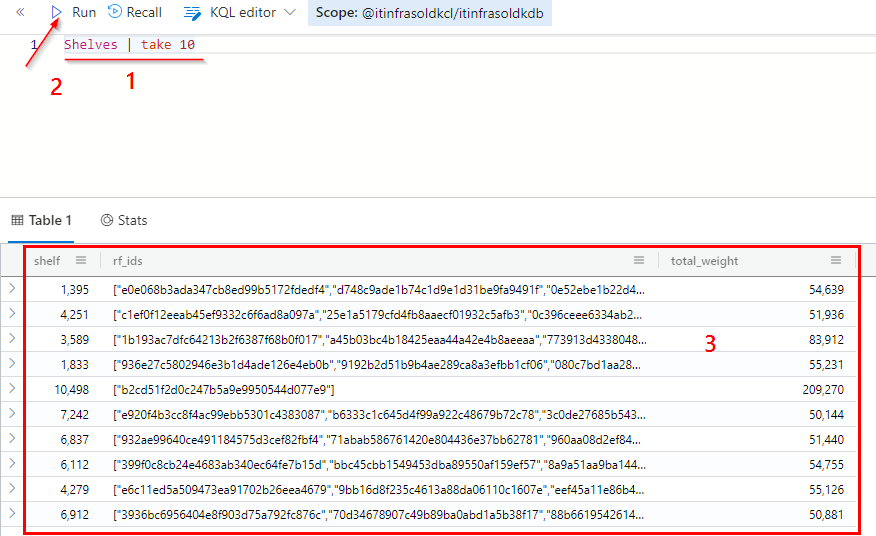
Based on the shown datastructure, it seems appropriate to make a table join, to sum up the weight of the individual books and finally to compare it with the digitally measured total weight.
Consequently, we need a sum - and a join - operation.
Creating the necessary KQL - Query:
Join:
To be able to perform a join, there must be a property that occurs in both tables. The RFID is a good choice for this.
Since the RFIDs in the Shelves table are only available as an array, we need to extract these values.
For this purpose the mv-expand operator can be a helpful option.
# Step 1
# Take 10 shelves, extract each RFID and convert them to a string
Shelves | take 10 | mv-expand rf_ids to typeof(string)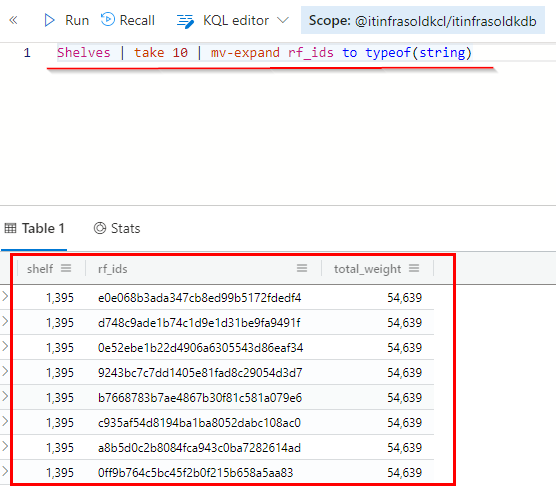
At this point, we are ready to merge the 2 tables.
# Step 2
# All measures from the previous step + union with the book table, where the
# property rf_ids must match the property rf_id
Shelves | take 10 | mv-expand rf_ids to typeof(string)| join (Books) on $left.rf_ids == $right.rf_id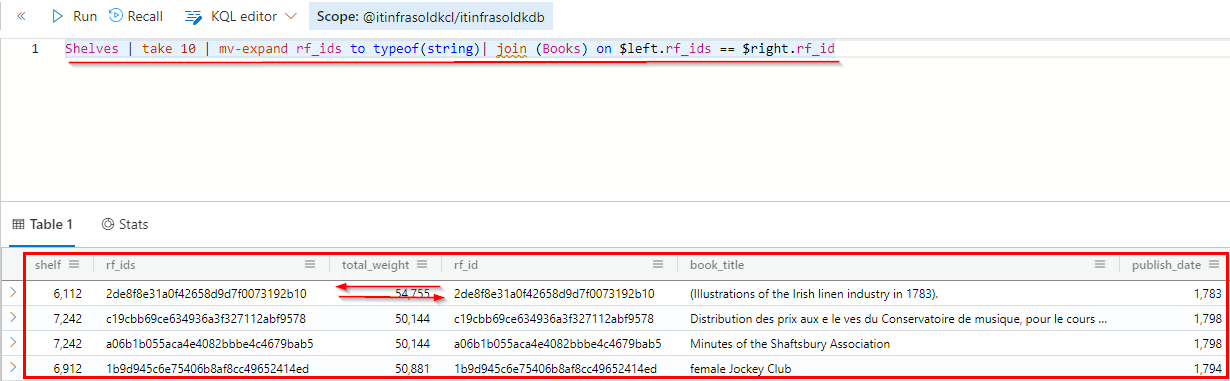
Sum:
Now that we have unified the tables it is time to summarize the weight of each book based on the shelves and compare it to the total weight.
In this step, we can remove the limit of 10 (take 10) shelves from the query, since the summarize operation reduces the number of records and therefore we will no longer get over a processing limit.
# Step 3
# All measures from the previous steps without the take 10 limitation + by
# shelf summarize operation leveraging a sum method on the weight_gram
# property
Shelves
|mv-expand rf_ids to typeof(string)
| join (Books) on $left.rf_ids == $right.rf_id
| summarize sum(weight_gram) by shelf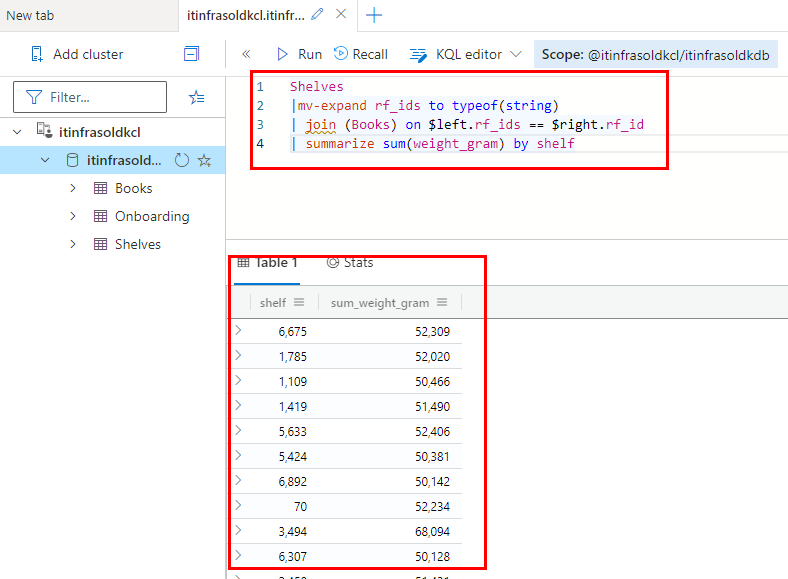
Now we have a list of all shelves with the summed weight of the individual books. This must now be compared with the total weight by calculating the difference between the summed weight and the total weight.
# Step 4
# All measures from the previous steps + extension of the
# summarize operation with the total_weight property + extension of the table
# with a difference column
Shelves
|mv-expand rf_ids to typeof(string)
| join (Books) on $left.rf_ids == $right.rf_id
| summarize sum(weight_gram) by shelf,total_weight
| extend diff = total_weight - sum_weight_gram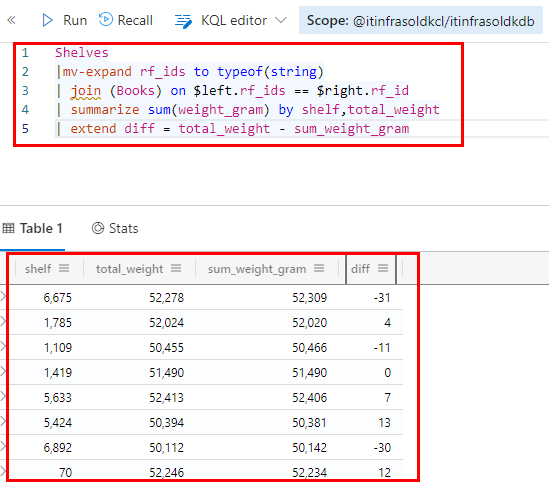
To identify the shelve that has the largest weight mismatch, we use the sumarize operation again
# Step 5
# All measures from the previous steps + summarize operation leveraging the arg_max method on the diff property
Shelves
|mv-expand rf_ids to typeof(string)
| join (Books) on $left.rf_ids == $right.rf_id
| summarize sum(weight_gram) by shelf,total_weight
| extend diff = total_weight - sum_weight_gram
| summarize arg_max(diff,*) 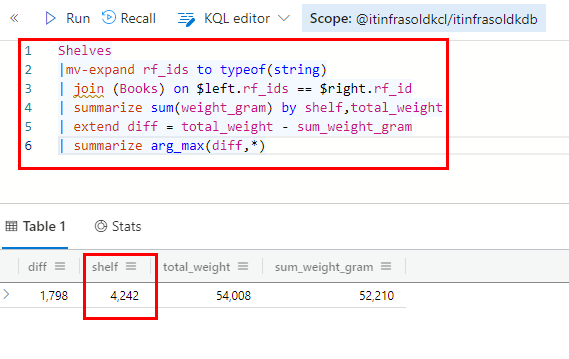
The Reward:
References:
Kusto Detective Agency: Hints and my experience
https://it-infrastructure.solutions/kusto-detective-agency-part1/